Spark in Kubernetes mode on an RBAC AKS cluster
Spark Kubernetes mode powered by Azure
As you know, Apache Spark can make use of different engines to manage resources for drivers and executors, engines like Hadoop YARN or Spark’s own master mode.
For a few releases now Spark can also use Kubernetes (k8s) as cluster manager, as documented here.
Documentation is pretty accurate, but at least when I first tested this, with Spark 2.4.0, I did stumble upon a few gotcha’s, especially with regards to the role-based access control (RBAC) of the k8s cluster. So all of the below applies to 2.4.0; newer versions might offer simplified setups and configuration, especially around BDAP k8s authentication.
In this little elaboration we explicitly refer to Azure Kubernetes Services (AKS) for the infrastructure. It turns out that other clouds, such as Google Cloud Platform, have more specific support, with projects such as Kubernetes Operator.
Infrastructure
To get started, create an AKS cluster in your subscription of choice, but be careful to set RBAC mode on: it cannot be turned on at runtime! A few important points:
- k8s version should be 1.6 at least, the AKS default version should do it
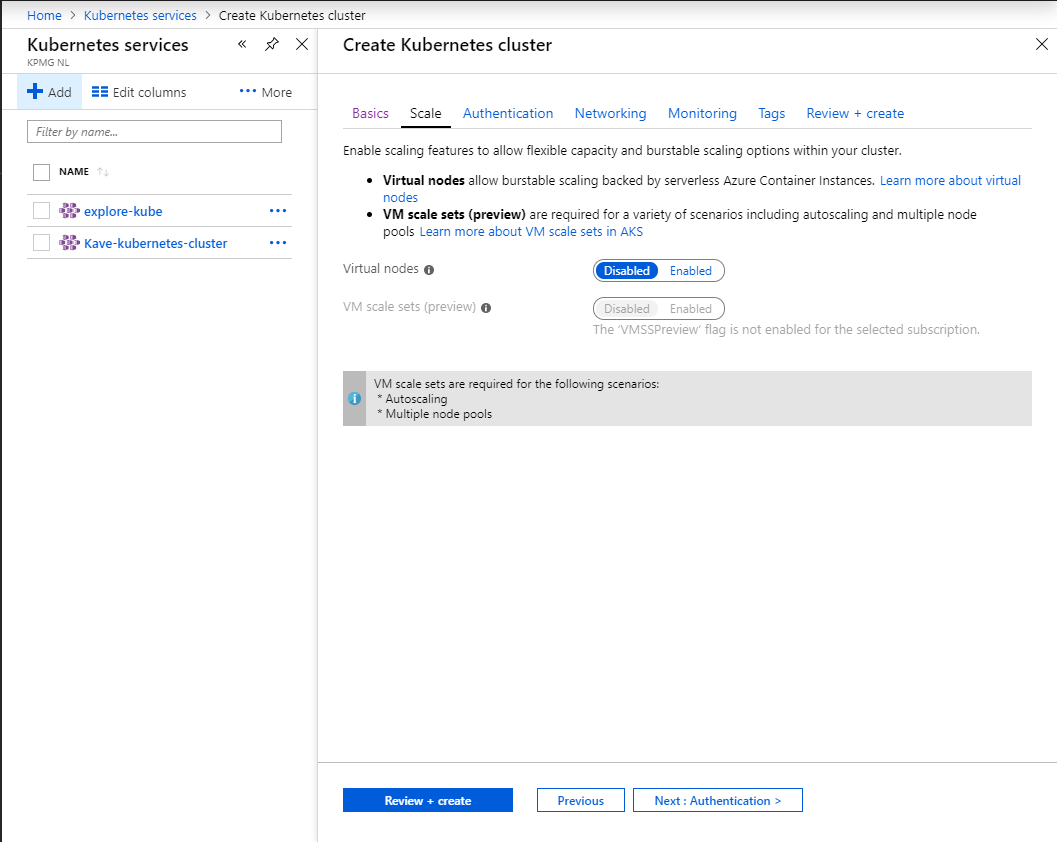
- AKS virtual nodes mode with Spark did not work when I tested it
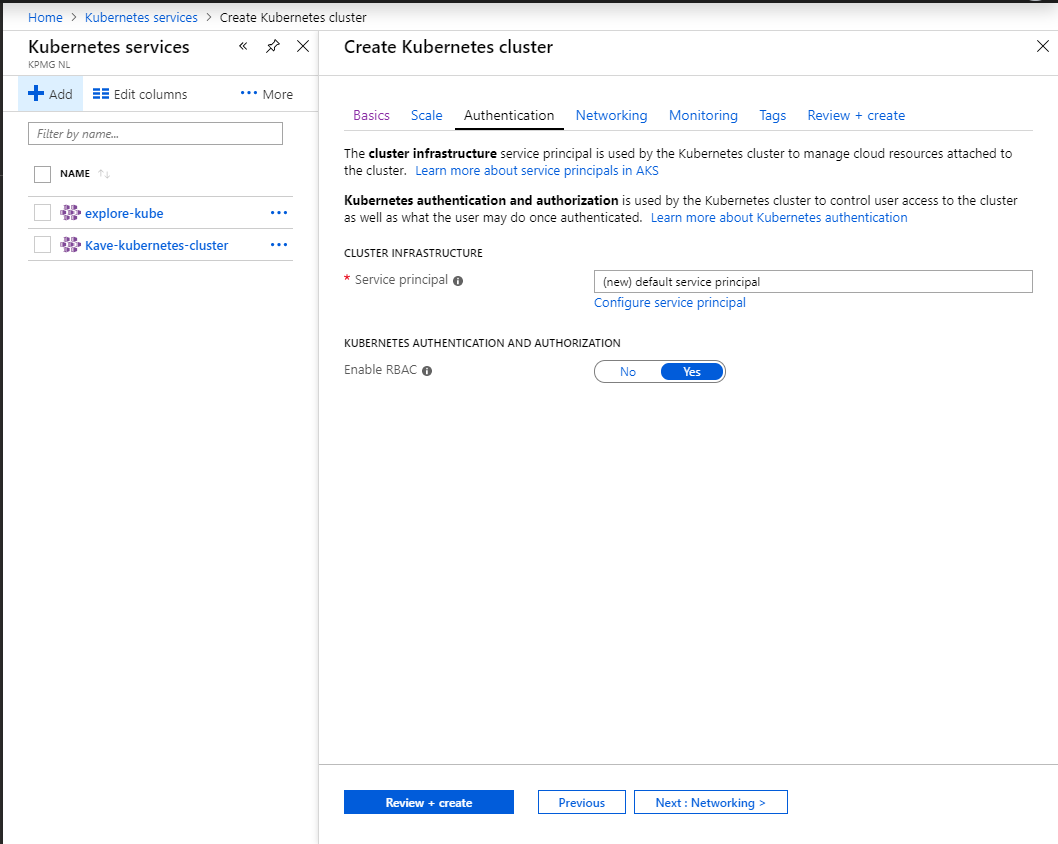
- you will need an infra service principal (Active Directory - AD - application)
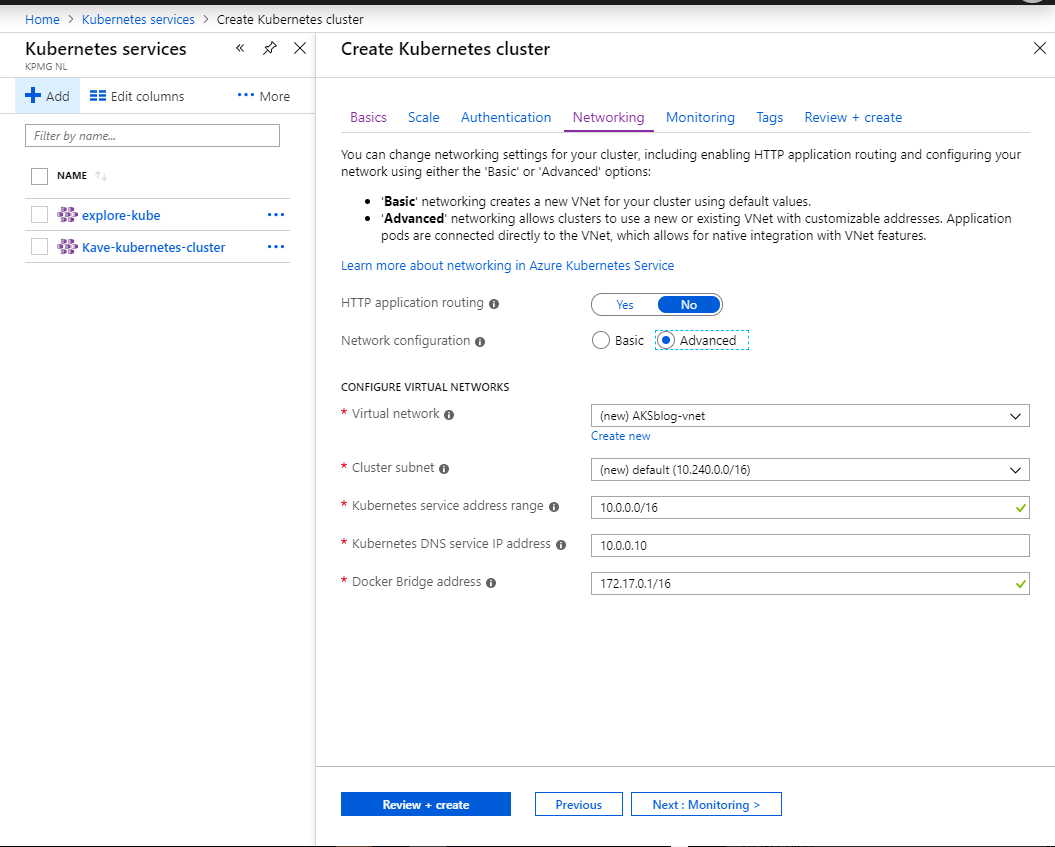
- while not mandatory, the advanced network configuration is suggested
- since AKS billing can become quite relevant, a good idea to tag the resource
You can quickly setup the cluster through the wizard:
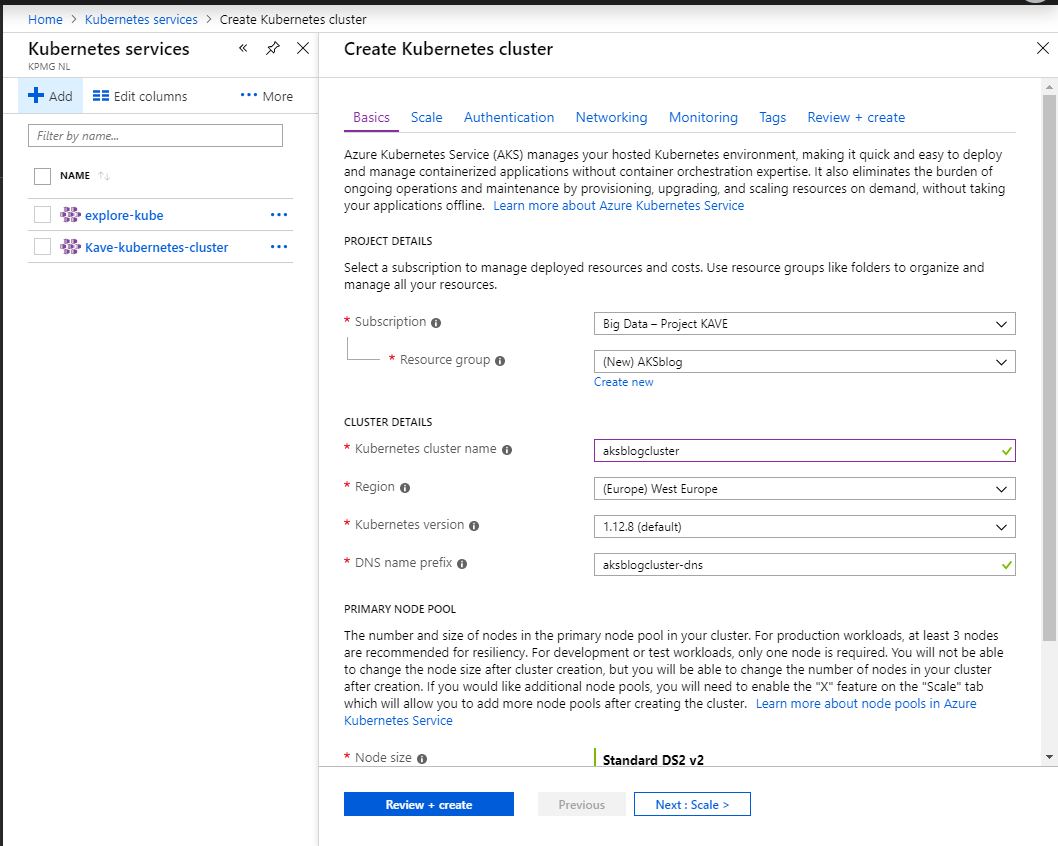
The infra AD app is the one the setup will use to talk to the Azure API to create the needed cluster resources, VMs for example: the k8s node will be actual virtual machines of the specified size.
Custom network control is always a good idea in Azure, with any kind of managed resource, think about an HDInsight cluster or a Databricks workbench - you may want to connect other resources directly, or have fine-grained control on the firewalling, all of this is not possible if the network is hidden, thus internally managed.
About tagging, this is also a good practice for any resource, especially if a subscription is in use by multiple teams or groups and you want to specify the cost centers with detail.
Finally on virtual nodes. The virtual nodes setup for AKS basically leverages Azure Container Instances to dynamically provide pods as needed. Theoretically this should be transparent to Spark itself, but when the job actually starts it fails immediately expecting some log file which is not there yet; it seems there is something going wrong in this unit.
Deployment automation
Just like any other Azure resource, we can manage its deployment with the Azure Resource Management (ARM) templates, see here for a full setup. You can readily setup the ARM-based deployment as an Azure DevOps release pipeline.
Access Control - Identity Access Management
When setting up in RBAC mode as we do, it is very important to configure the accesses right from an AD perspective. Next to the usual Contributor and Owner roles, AKS has a specific Azure Kubernetes Service Cluster User Role: AD users and groups needing working access to the cluster need to get this role assigned; replace User with Admin and find the administrative role. While a reader role is also handy, contributor and higher roles shall be given only to those in charge of managing the solution, e.g. an infrastructure team.
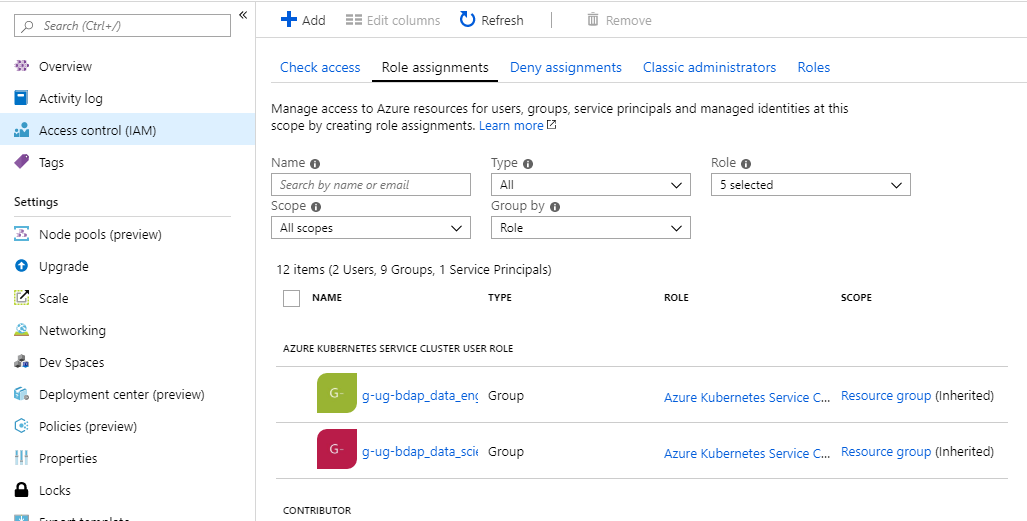
Having the admin role assigned means that the user will be able to connect to the cluster with k8s admin privileges, more on this below.
Spark in k8s mode
Just like YARN mode uses YARN containers to provision the driver and executors of a Spark program, in Kubernetes mode pods will be used. The point is that in an RBAC setup Spark performs authenticated resource requests to the k8s API server: you are personally asking for two pods for your driver and executor. Anything applying to an RBACed solution also applies to our cluster, with two specific points:
-
we need to properly configure the agent which is performing API requests on our behalf
-
by introducing RBAC, specific per-user configuration can be implemented, for example resource quotas - you may ask at most say five pods, and consume no more than 250 MB memory and 1 CPU.
A Spark program becomes then specified as one container image, typically Docker, tobe spawned. In normal scenario’s you will not need a specific image for executors, the same image as for the driver will be used.
A two-step authentication
Let us assume we will be firing up our jobs with spark-submit. We will need to talk to the k8s API for resources in two phases:
- from the terminal, asking to spawn a pod for the driver
- from the driver, asking pods for executors
See here for all the relevant properties. The spark.kubernetes.authenticate props are those we want to look at. As you see we have the submission and driver sections, and multiple ways to authenticate, OAuth, certificate and service accounts . To complicate further, values may be passed as arguments or mounted as k8s secrets.
After some pondering and tests, we will go for the following:
- providing the OAuth token to the Spark submitter,
spark.kubernetes.authenticate.submission.oauthToken - setting up a service account for the driver,
spark.kubernetes.authenticate.driver.serviceAccountName
At least now there are two mayor limitations in the Spark k8s mode for AKS:
- we cannot use a service account for submission too (a service account is not a k8s service actually and it may not be accessed remotely))
- certificate authentication is an option for admin mode only: when merging the configuration in non-admin, the certificate information is not sent back to the client (see below)
Getting the keys right
So in order to successfully launch a Spark job we need two pieces of information:
- an OAuth key
- a dedicated service account
OAuth key
We assume you have downloaded the Azure CLI tools as well as kubectl installed via az aks install-cli on Linux or OSX.
To get a cluster connection give the following:
az loginaz account set --subscription "$SUBSCRIPTION"az aks get-credentials -g $AKS_RESOURCE_GROUP -n $AKS_CLUSTER_NAME $ADMIN
after initializing the needed environment variables; optionally set ADMIN=--admin.
On a successful authentication the ~/.kube/config file will appear, containing the OAuth access token among others. Extract it with the following:
awk '/access-token:/ {print $2}' ~/.kube/config | tr -d "\r" | tr -d "\n" > ~/.kube/oauthToken
TOKEN=$(cat ~/.kube/oauthToken)
The TOKEN variable contains the value for the submission.oauthToken property above. In that configuration file you will also find the certificate setup, but only if in admin mode as said; certificate authentication is not supported by AKS anyway, see here.
k8s roles and accounts
To properly setup our personal Kubernetes environment in RBAC mode for Spark, we will need specific configuration. In particular:
- proper roles to be able to create and monitor pods
- a binding of such roles to our account
- a service account
You can read more about this here and in the Spark documentation. For convenience here is a couple YAML files:
To kubectl apply those you will need to get a cluster shell as admin with the --admin switch above. Notice that these are templates: you will need to fill in the variables first, such as a username and your user Active Directory ID.
When done, you will have an own service account alias called spark, which will be the value for driver.serviceAccountName. While it is possible to have a cluster-wide service account for all users, it is suggested to keep them personal for a better separation of concerns in terms of security.
A complete Spark properties configuration
We are now ready to create the spark.properties file we will provide to spark-submit. It will look like:
spark.master <CLUSTER>
spark.deploy.mode cluster
spark.submit.deployMode cluster
spark.executor.instances 3
spark.kubernetes.container.image.pullPolicy Always
spark.kubernetes.pyspark.pythonVersion 3
spark.kubernetes.authenticate.submission.oauthToken <TOKEN>
spark.kubernetes.authenticate.driver.serviceAccountName spark
where you will replace <TOKEN> with the value of the $TOKEN variable above, and <CLUSTER> is the k8s://https:// address of your AKS cluster (copy that from the portal). If you will launch the Spark submit from inside the cluster, say for example on a test environment running inside a pod, you may just use the local reference k8s://https://kubernetes.default.svc:443.
A few comments:
-
the number of instances must be satisfied with your quota if set: if you ask for three executors but only have one pod left for example, that one will go to the driver and your job will keep hanging until you free up other pods, by killing existing jobs for example
-
a specfied image will be always pulled: this avoids situations where the image you are firing gets stale, and it is very little time overhead for nontrivial jobs anyways
-
the Python version should match the version of your driver image program; for PySpark on k8s, version 3 only should be used
-
tokens will expire after a while, with the Azure AD default policies it is one hour, but this file needs to be kept secret at all times, keep it in your home but do not share it
-
token expiration also means that you will have to update the token in the configuration every hour: to get a new token just repeat the credentials download again, or perform any
kubectlcommand
Test program
We will use Docker of course, and before we start, make sure you have a Docker repo up and running. A very easy option is just to create an Azure Container Registry in the same resource group as the cluster.
Let us try out a very simple PySpark program just to make sure everything is fine. Find an example program here.
As you can see this is based on a spark-py:v2.4.0 image: how do we make that?
Base PySpark image
How to build the PySpark spark-py container image:
- download the Spark source code from the official website, e.g.
spark-2.4.0.tgz - unzip and give (needs
mvn):./build/mvn -Pkubernetes -DskipTests -Phadoop-2.8 -Dhadoop.version=2.8.1 clean packagebin/docker-image-tool.sh -r aksblog.azurecr.io/aksblog -t v2.4.0 buildbin/docker-image-tool.sh -r aksblog.azurecr.io/aksblog -t v2.4.0 push
The Hadoop version is of particular relevance because we need to have a version compatible with the specific Azure jars - not shipped with Spark itself - if we want to have Spark jobs talking to the Azure DataLake Storage for example.
Once a Hadoop version is fixed, getting the latest greatest for those jars should work.
Launching the Spark jobs
You should have pushed both the base and test PySpark images to the repository now. Properties file is also ready. That means we are ready to launch the job! Give:
spark-submit --conf spark.kubernetes.namespace=$NAMESPACE --conf spark.kubernetes.container.image=aksblog.azurecr.io/aksblog/spark-example:v2.4.0 --properties-file spark.properties --name spark-example /app/bin/run.py
where $NAMESPACE points to your personal k8s namespace created in the YAMLs above, the image is the test Spark program and the Python program is an actual path in the image itself. It goes without saying that you should have Spark 2.4.0 properly installed locally.
Follow through the logs now; once the job successfully starts, a kubectl get pods in your namespace will show one driver pod and a number of executor pods.
Congratulations, Spark on Kubernetes mission accomplished!
Final considerations
After working with this setup for a while, it seems to me that Spark is not really a first-class citizen on Azure Kubernetes Services, even if there are quite a few Azure blogs covering the basics.
All of the above is fully documented in the respective projects only, and that is why it feels perhaps a little cumbersome - a full-stack walkthrough was not there when we first digged into this (well now there is this blog!).
For higher freedom while keeping the configuration headache at a minimum, deploying Spark on Kubernetes feels easier on Google. But the real extra point Azure gets here is the seamless and advanced Active Directory configuration, guaranteeing control on the access and a clean mapping between authentication, resource management and control.
Have fun spawning pods in Spark!