Testing stateful streaming applications - an example in Spark
Testing a stateful application, what about it?
Over the last couple of years more and more organizations want to have processes which act immediately upon events as they come. This is definitely a big trend, and it usually goes under the umbrella term streaming applications, but the actual keyword, and proper programming paradigm, is stream processing.
Streaming applications as regular computer programs, well we need to test them somehow, how about this? For a stateless streaming application, one which does not retain any memory of what it sees, things are rather simple. Could we say the same about applications which are stateful instead, those which compute some state in terms of some function of what they see? In this post we give a real life example and show that of course it can be done, but it is also fun!
There will be no theoretical preamble to this discussion; first of all because I do not know anything relevant in this sense, but also because this wants to be a quick peek. You are very welcome to show pointers on this discussion: I have not managed to find anything very interesting myself, but I am pretty sure there is. As usual: build on what other people have built!
Frameworks and libraries
There are a number of solutions to implement streaming pipelines. In our walkthrough we present the concepts with Apache Spark in Scala.
In particular, we refer to the classic Spark Streaming API, so discretized streams, just to be clear. The new way of doing streams in Spark is using structured streaming. In this production exercise we had to choose for the former as the latter does not provide everything, e.g. stream2stream joins.
Furthermore, we use Holden Karau’s spark-testing-base. Holden made a great job in fitting a nice integration on top of ScalaTest, exposing enough stuff for rather advanced scenarios. An associated project, also fundamental in the development, is Scalactic.
The issue at hand
In this exercise our task is to reimplement a legacy processing pipeline, and the behavior is an invariant. This means that basically the new implementation must behave exactly as the old one, modulo some numerical tolerance because the technologies, and therefore data type implementations, in use are completely different.
The most relevant point from this is then: we have data to test against! In particular, we are able to provide an input for the streaming data and an output to be produced by the processor having seen such streaming input.
Let us build up some notation to better address this and get to understand what we are exactly talking about, before even stepping into the code. Again bear with me if this is not that orthodox - please point out relevant theory in case.
We can model a stream as an infinite set:
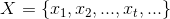
at every instant a new event comes in. The state of the stream is represented by some set and it is defined, at every instant, as the result of applying some function to the new incoming event building up on what we have already; the state of the application may be conveniently modeled as the sequence:
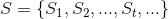
where some initial state 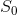 is given and the generic state at time
is given and the generic state at time 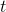 is given by:
is given by:
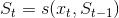
to conveniently look at the current state only, instead of carrying all the events 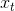 from the past. This is basically an order-one recurrence - starting from a predefined state, at every tick we are perfectly ready to compute the new state.
from the past. This is basically an order-one recurrence - starting from a predefined state, at every tick we are perfectly ready to compute the new state.
But what if we needed some more state to be built up, before we can be able to produce the current tick? Taking a step back, in this simple writing if you unfold the recurrence the state at time , so 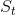 , is built as a function of the initial state and the events so far:
, is built as a function of the initial state and the events so far:
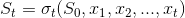
and what if this is not defined? Coming back to planet earth: have we seen enough events in the stream for the state to be defined? Say in the application we are asked: for a new car, determine the the driver profile (occasional, commuter, taxi driver etc) after no less than eight days of usage. Before eight days we could not really dare to say anything, the state is undefined!
Now in our testing scenario we are given some stream 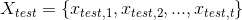 and the sequence of state sets
and the sequence of state sets 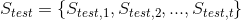 our application is expected to emit seeing that as an input. These two sequences are extracts of a run of the original application: think that the old application is running and at some point the input messages, and the state produced for those, are recorded.
our application is expected to emit seeing that as an input. These two sequences are extracts of a run of the original application: think that the old application is running and at some point the input messages, and the state produced for those, are recorded.
Again, assume this eight-day horizon for the application. The very first eight shots of our stateful application, so the set 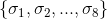 will be undefined. To check whether our new implementation is correct or not, we have to evaluate the equality:
will be undefined. To check whether our new implementation is correct or not, we have to evaluate the equality:
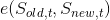
for every time . Until 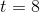 this equality is not well defined: while the state recorded on the old app is legit, what we are producing on the side of the new app is not defined, because this is a cold start and we are missing whatever the old app had before. The eight time ticks is actually analogous to what in other areas is referred to as burn-in period.
this equality is not well defined: while the state recorded on the old app is legit, what we are producing on the side of the new app is not defined, because this is a cold start and we are missing whatever the old app had before. The eight time ticks is actually analogous to what in other areas is referred to as burn-in period.
In a nutshell, in the codeful part of this blog we show how to implement such scenarios in an elegant way in Spark streaming. How do we go about asking the testing framework to discard a prefix, and live happily thereafter?
Setting up
Let us continue with the analogy of the car application: our streaming application maintains, for every car we monitor, a profile of its driver. The right profile is inferred from collecting some instant info sent out from the car, let’s just say the GPS position and speed.
case class InstantInfo(timestamp: Instant, gps: GPS, speed: Double, car: Car)
In real life these events are coming from some source, these days Kafka and Spark make a great duo, but this is not relevant here. The profile is simply:
sealed trait Profile
case object Commuter extends Profile
case object Racer extends Profile
case object Unknown extends Profile
case class DriverState(chronology: SortedMap[Instant, InstantInfo], avgSpeed: Double, profile: Profile) { //we will fill this in below }
To write our stateful application, we will use the mapWithState method. See some (outdated) info here and an excellent discussion here. About this API, let us say that it is the successor of the epic updateStateByKey; the interface is a little more complicated but it does not grow linearly in the number of stream events like its predecessor did.
A streaming application
The class DriverState represents the current state for a specific car / driver (let’s use these terms interchangeably); all together, they make up the big at the current time. Every time we see a new car beacon come in, there are two cases:
- the car is seen for the first time, it is not known to the system yet: some initial state will be defined for it, collecting the very first measurement
- the car is known and a state for it can be found; this state is updated and, if we have seen enough measurements, then we may say something about the driver profile
Let us model this state as a self-contained assignment-free class, functional style:
case class DriverState(chronology: SortedMap[Instant, InstantInfo], avgSpeed: Double, profile: Profile) {
def update(info: InstantInfo) = {
val updatedChronology = chronology + ((info.timestamp.truncatedTo(ChronoUnit.HOURS), info))
val avgSpeed = (updatedChronology.values.map(_.speed).sum)/updatedChronology.values.size
if (updatedChronology.size <= Params.horizon) copy(chronology = updatedChronology, avgSpeed = avgSpeed, profile = Unknown)
else {
val filteredChronology = updatedChronology.drop(1)
if (avgSpeed < 60) copy(chronology = filteredChronology, avgSpeed = avgSpeed, profile = Commuter)
else copy(chronology = filteredChronology, avgSpeed = avgSpeed, profile = Racer)
}
}
}
nevermind the business logic, that is not important. So, get a new measurement in, add it to the history for the car as the record of the hour behavior, check if the state may be updated. What is really crucial though is that the behavior is forgetful, what do we mean?
The current state is defined by looking at a finite horizon in the past. This is the property of applications which can catch up - real life processes are always time-limited, and a streaming process even more because otherwise the state would grow indefinitely. This is implemented by dropping the oldest record, every time, after we have read some (how many is that horizon variable).
And now, the stream definition:
object CollectInstantInfo {
type FrameNumber = Int
def updateDriverState(fn: FrameNumber, value: Option[InstantInfo], state: State[DriverState]): Option[(FrameNumber, DriverState)] = Some(
fn ->
{
if (state.exists) {
val newState =
if (value.isDefined) state.get.update(value.get)
else state.get
state.update(newState)
newState
}
else {
val newState =
if (value.isDefined) DriverState().update(value.get)
else DriverState()
state.update(newState)
newState
}
}
)
def createStream(ds: DStream[(Int, InstantInfo)], outputFile: String): DStream[(CollectInstantInfo.FrameNumber, DriverState)] = {
val spec = StateSpec.function(updateDriverState _)
val mapped = ds.mapWithState(spec)
val mappedFlat = mapped.flatMap{ x => x }
mappedFlat
}
}
The createStream method is our entry point: it accepts the incoming stream of messages 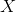 and creates a global state
and creates a global state 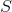 . There are three operations:
. There are three operations:
- define a method to update the state; this is our
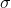 function
function - application: compute the sigma function on the states
- emission: return the projection of the
State on a particular car (and return this)
There are many other functionalities Spark supports here, for example setting a timeout after which long-not-seen entries are discarded, choosing an initial state . Spark requires the input stream to be key-paired in order to let us define a state, a state instance is always linked to a key entry.
The sigma function has some noise because of the Options all around, but what it does is implementing the two cases newcar vs oldcar explained above; for every encoming car in the stream, a state is created or updated.
We can easily create a main to drop an input and output file for us to test. Even better, we will make a self-contained unit test taking care of creating the needed test data and try things out - smooth!
Are we there yet?
The test suite does a few things for us:
- generates a number of random records for the stream
- computes a full test state
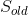 and serializes it
and serializes it - defines a function to test the performance of the “new” streamer against the data of the full test state, ideally produced by some “old” implementation
- properly configures the testing framework
- executes the run with a specified burn-in, which is creating a and testing it with the equality
If we ask our new stream processor to calculate a state from the input file, the result would be completely different from the test state, until some time is hit. Before this point, an equality function is not defined - this is until we stay in the famous initial sequence - we have to discard this.
We will have to let two streams be compared in Spark, the old and new one, arguments to the equality function. For the comparison to yield a true, which means a green test, we need to know where to cut, somehow. This cut point is where our new application has caught up so to say - it is aligned because the past state it is not presented with has no more effect, the window horizon has elapsed and we have discarded what we had to discard.
Usually, and especially in this artificial reproduction, this is not exactly the length of the window, in our case a few days, but at some point we need to stop discarding and sync up.
The equality function is:
implicit def driverStatesEq(burnInDate: Instant = Instant.EPOCH): Equality[DriverState] = new Equality[DriverState] {
private val tolerance = 0.0005f
def areEqual(a: DriverState, b: Any): Boolean = (a, b) match {
case (_, ds: DriverState) if ds.chronology.isEmpty =>
println("Skipping comparison (stream record with empty chronology)")
true
case (_, ds: DriverState) if ds.chronology.last._1 isBefore burnInDate =>
println("Skipping comparison (burn-in)")
true
case (DriverState(chronologyA, avgSpeedA, profileA), DriverState(chronologyB, avgSpeedB, profileB)) =>
println("Comparing!")
(avgSpeedA === avgSpeedB +- tolerance) &&
profileA == profileB
case _ => false
}
}
(this actually wrapped with some boilerplate in the code, but nevermind). The trick to the whole idea is the first case: if the syncing time has not come yet, we do not want to compare the values, just confirm with a true. It is now time to reap we sow and implement a nice demo in the form of a unit test.
Putting it all together
We are going to write a test now; to be tediously formal, this is a functional test - the pipeline is a program of its own and we are testing part of it (in our case it is just one part so ok). A hint at how powerful things can get is in the code and it goes by the name of function composition!
The nude equality function is not enough the make things work in the Spark testing framework. Among other things we need the following override:
override def verifyOutput[V: ClassTag](
output: Seq[Seq[V]],
expectedOutput: Seq[Seq[V]],
ordered: Boolean
) (implicit equality: Equality[V]): Unit = {
if (ordered) {
val x = output.flatten
val y = expectedOutput.flatten
if (x.size != y.size) {
println(s"Sizes do not match! ${x.size}, ${y.size}, auto-resizing")
val resizedY = y.drop(y.size-x.size)
println(s"Sizes are now: ${x.size}, ${resizedY.size}")
x zip resizedY foreach { case (a, b) =>
assert(b === a)
}
}
}
else throw new IllegalArgumentException("Only list-based comparison is supported for this override")
}
See the code for the details, but the framework tries to model the batching of a Spark application, which is something we do not need here, and the output sizes and forms are not a function of the inputs alone - we need to reshape the lists a little.
As hinted above, we will test functional style of course:
def operation(hb: DStream[(Int, InstantInfo)]) = CollectInstantInfo.createStream(hb, outputFile)
this is the streaming operation. In real life a pipeline is composed by multiple of those, but the cool thing is that you can mix and match for tests the whole flow if you use them as functions!
The core of the exercise is thus:
val eq = equality(startingDay.plus(Params.horizon+25,ChronoUnit.DAYS))
testOperation(Seq(partialData.flatten), operation, Seq(expected), ordered = true)(implicitly[ClassTag[(Int, InstantInfo)]], implicitly[ClassTag[(Int, DriverState)]], eq)
so we are instantiating the equality with a desired burn-in and fire off the operation: for a specified input we expect a given output in memory, and this state must be equal to the serialized state we read back, which was created in the first (virtual) test.
It is definitely a good idea to fiddle around with the parameters, such as the number of initial messages and the burn-in date, to even break the code and get a feeling of what is going on.
Time to sleep
In this blog we have looked at an interesting scenario of stateful streams testing, with some - vague pseudo-math around it to get things firm. Not really sure this is like an everyday thing, but it is for sure very cool that I have implemented this on a real project, showing a guarantee that the new streaming implementation is consistent with the legacy solution.
Find the full code here, together with the other posts.
I would be very glad to welcome feedback and improvements, and if you have some question very glad to answer!
Thread.sleep(10000)